
Document management systems (DM) are all about building more efficiency in the filing processes and filing access in an office. Making the effort to install and learn the intricacies of document management is not a decision to be taken lightly. On the other hand my experience in our work in the Burlington area tells me that doing so is inevitably a good one and can lead organizations to see a quantum leap in efficiency in their operations affected by document production, filing and retrieval.
One of the key elements however is the ability to properly integrate the right tools for inputting data to the document management system. Most document management installations start out using manual data entry for keywords to support retrieval. There are many terms used for this process; keywords, index data, meta data are a few. Since I commonly use the term index data I will use it here, but it is interchangeable with the others referenced.
The purpose of index data is to help users retrieve documents without having to refernce a large number of documents. Ideally, they can run a search on the index data in the document management system and can get the exact document returned that matches the data. Of course in practice users often do not have all of the index information to use in the search and they have to deal with a subset of the documents to find their required one. This subset is often called a 'hitlist', the list of the documents that match the data entered into the search.
Index types
Full text search
One type of index process that is commonly discussed by new users is the ability to do full text optical character recognition (OCR) on the document instead of specifying index data.
There are vendors who promote this process as a way to simplify the data entry steps for electronic filing.
In my experience full text OCR never actually works for document retrieval purposes. The simply reason is that too often a search using a text string from a full text indexed DM system gives you a search that is akin to the results of a Google search for a popular term....many hundreds or thousands of pages which contain the text string, without context. Your ability to find what you look for is reduced.
Worse than that the full text search engines used in DM systems are nowheres as sophisticated as Google's search. They do simple text matching without context often returning the text string within words and phrases. Full text search has its place however. If used as a background process to be used when other forms of search are not known it can help reduce the result to a more manageable state than just scrolling through the whole list of files. As a primary search tool my experience says don't count on it, however.
File folder based indexes
Some products use a file folder naming system similar to the Microsoft windows based file structure. The positive to this type of structure is that it is familiar to users and it is relatively easy to create. Commonly referred to as library based structures (comes from the windows library or file manager format) documents are stored using a naming system and then organized into groupings of libraries of similar documents based upon common characteristics. This type of indexing can work however as systems and the file stores grows they become more complicated and cumbersome to manage and to build. For smaller systems they can work due to their simplicity but often start to break down as the file store grows over time.
Relational data based indexes
In my experience the most successful system of DM structure is the relational data base model. Using this model you determine key characteristics of your document groupings and then attach these characteristics to each document as reference pointers. Typical data fields are date, name, document type, company, organization grouping, etc.
Let's look at an accounts payable application as an example.
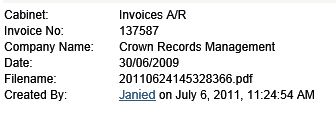 Typically individual invoices could be found if they were recorded with reference to the invoice number, date, amount, vendor name and perhaps the PO number that the purchase related to. When a document is stored into the system the DM application is set up to permit attaching index data to each document using these fields. The index data is entered into a relational data base with a reference pointer to the appropriate document, either a scanned document or an electronically filed document. When the document is needed for retrieval a search is run using some or all of the index data fields to search. Depending upon the field(s) chosen either the individual document is delivered or a small subset of documents (hitlist) is delivered permitting the required document to be opened and used as needed.
Typically individual invoices could be found if they were recorded with reference to the invoice number, date, amount, vendor name and perhaps the PO number that the purchase related to. When a document is stored into the system the DM application is set up to permit attaching index data to each document using these fields. The index data is entered into a relational data base with a reference pointer to the appropriate document, either a scanned document or an electronically filed document. When the document is needed for retrieval a search is run using some or all of the index data fields to search. Depending upon the field(s) chosen either the individual document is delivered or a small subset of documents (hitlist) is delivered permitting the required document to be opened and used as needed.

Learning how to build these types of index tables correctly to match with the workflow needs of a client is one of the attributes a good DM vendor provides. You need enough fields to be able to closely find the documents in the system, while making the input process not too cumbersome or confusing to complicate the data entry. This process is an art not necessarily as science and the design in always customized for a client so that language and field choices match the way the clients environment operates.
How does it get accomplished?
Initially at start up these types of indexes are commonly entered using manual data entry, however there are ways and tools which can make it much easier and much more accurate using automated methods. This is a topic best left to another post...so watch for step two fo the document index structure to come.
What type of indexing does your DM support? How has it worked for you? Did you build a good reference index for easy searching?
Share your experience....
Lee K


Photo Credit: From Sentryfile Document Management System

